简单的Rosenblatt感知器 为了使得到的数据更加直观,我使用了python的matplotlib绘制图像
首先写一个可以获取散点的函数
1 2 3 4 5 6 7 import numpy as np
调用它并使其在坐标系中打印出来
1 2 3 4 5 6 7 8 9 10 11 import dataset
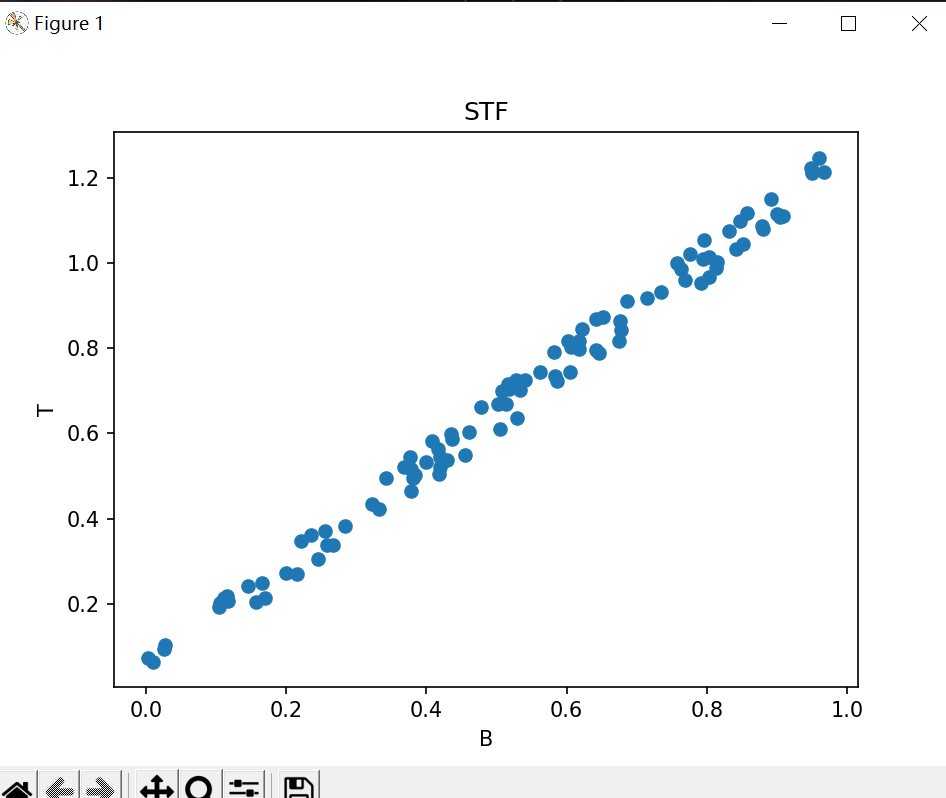
我们可以得到这样的一个图像
之后任意设定一个权重值w为0.1
用标准答案减去该参数计算得到的结果得到一个误差,用原来的w加上alpha误差 B(乘B是为了应对B为负数时,可能导致结果正好相反的情况,学习率alpha是为了控制调整的幅度,以免幅度过大错过最佳点)作为新的w,再一次进行运算。通过误差修正参数,这就是Rosenblatt感知器的学习过程。当然,这个公式在数学上是收敛的,Novikoff(1962)证明如果训练集 是线性分隔的,那么感知器算法可以在有限次迭代后收敛,然而,如果训练集不是线性分隔的,那么这个算法则不能确保会收敛。以下代码简单的实现了 Rosenblatt感知器的学习过程 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import dataset
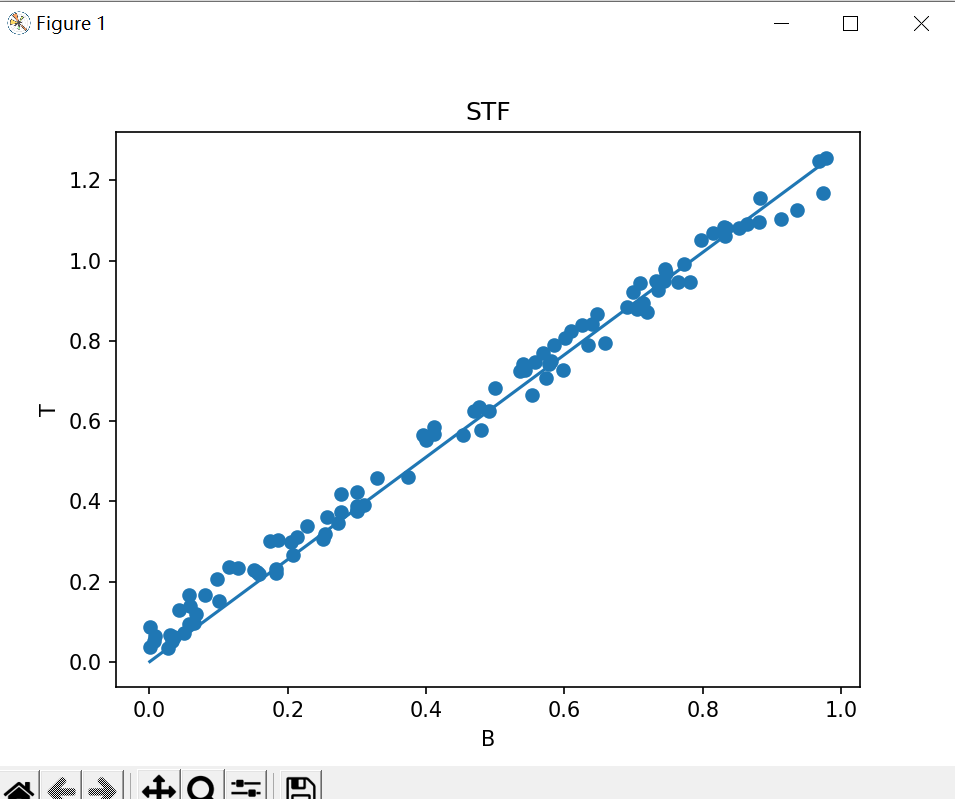
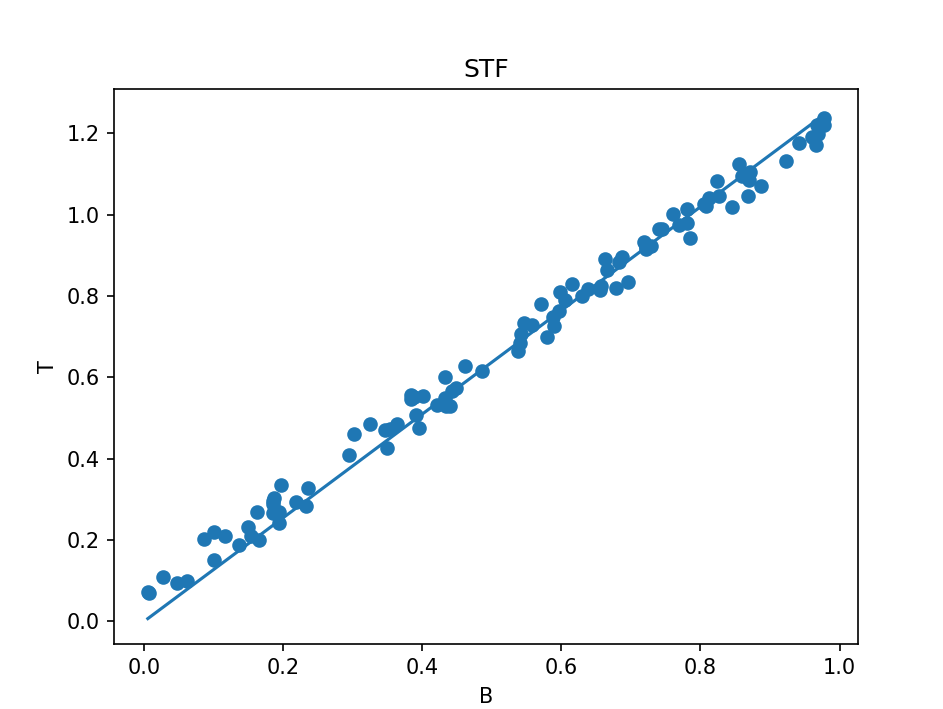
这样,运行后就可以得到一条与散点拟合的线
之后任意设定一个权重值w为0.1
用标准答案减去该参数计算得到的结果得到一个误差,用原来的w加上alpha误差 B(乘B是为了应对B为负数时,可能导致结果正好相反的情况,学习率alpha是为了控制调整的幅度,以免幅度过大错过最佳点)作为新的w,再一次进行运算。通过误差修正参数,这就是Rosenblatt感知器的学习过程。当然,这个公式在数学上是收敛的,Novikoff(1962)证明如果训练集 是线性分隔的,那么感知器算法可以在有限次迭代后收敛,然而,如果训练集不是线性分隔的,那么这个算法则不能确保会收敛。以下代码简单的实现了 Rosenblatt感知器的学习过程 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import dataset
这样,运行后就可以得到一条与散点拟合的线
方差代价函数 Rosenblatt感知器 其本身在现代神经网络研究中已经并不常用了,但我们依旧能从其中学习到参数的自适应调整是一个人工神经元的精髓。
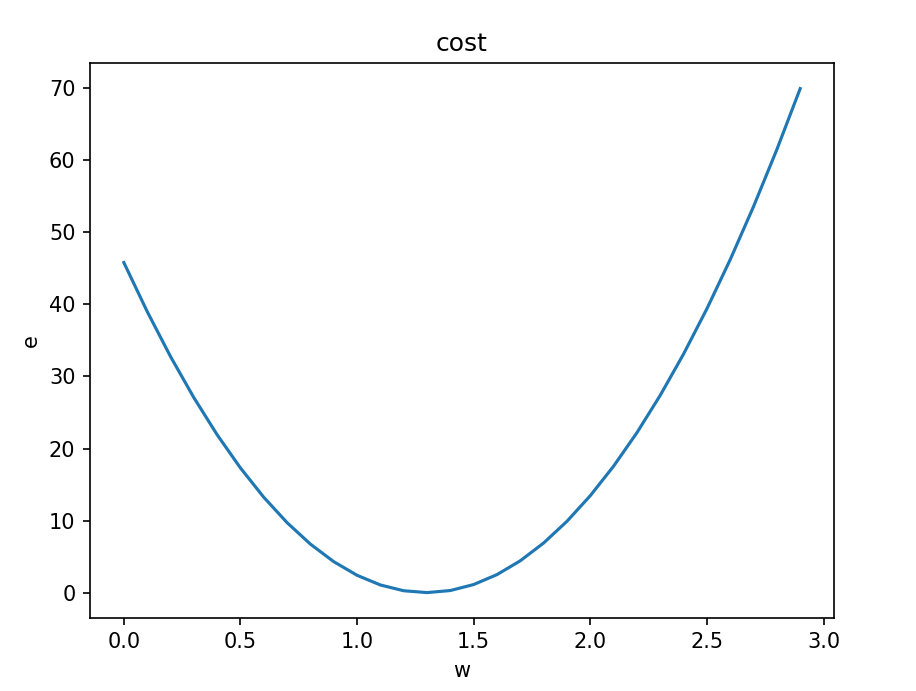
我们可以使用方差代价函数来评估误差从而达到参数的自适应调整。此时我们再次随便设定一个w,用统计到的数据去评估w的准确性,即回归分析。而我们可以使用最小二乘法来实现。我们将w作为自变量,误差e作为因变量,得到一个新的函数,即代价函数。他展现出当w取不同值时对于环境中问题数据进行预测时产生的误差e。因为他是一个二次函数,我们就可以利用它的最低点的w(此时e最小)带回预测函数,以此实现对参数w的自适应调整。
在之前代码的基础上进行修改,我们可以得到下面的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import dataset
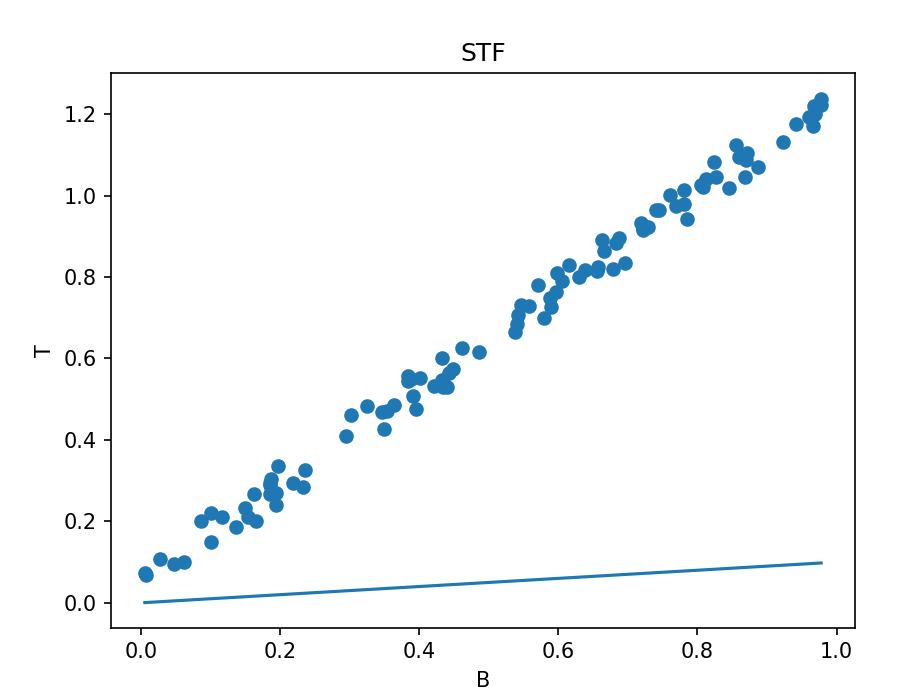
运行后得到三幅图