在之前的学习中我一直使用的是方程的形式进行前向传播梯度下降与反向传播。然而随着输入参数与隐藏层的增多,方程形式似乎不再能胜任如此复杂的工作,这时候就需要引入另一个数学工具——矩阵。
numpy库是一个强大的数学计算库,使用它可以让矩阵的计算变得简单许多。
这是利用方程的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 w1 = 0.1
这是利用数组的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 W = np.array([0.1, 0.1])
可以很直观的发现,使用数组(矩阵)时,代码量会少很多。并且面对越多的输入与隐藏层时,它的优势就会越明显。
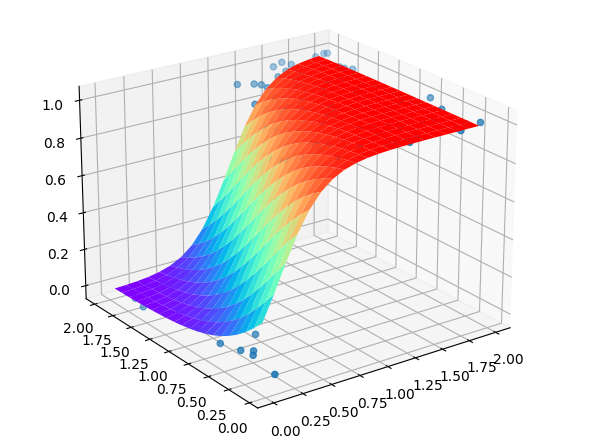
当然,它的拟合度也非常的好。
但是,在面对更加复杂的机器学习,比如卷积神经网络,使用这种编写底层代码的方式将会是个大工程。这时候,Keras就自然而然的进入了我的视野,正如它官网上那样:你恰好发现了Keras
现在,是时候走出对神经网络底层知识的学习,开始进入应用层的大门了。
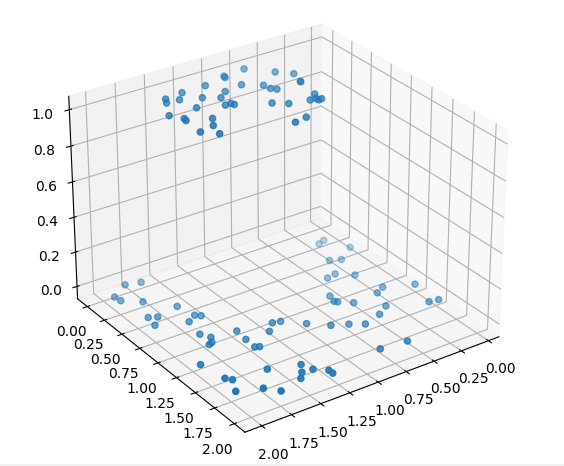
为了展现出Keras相较于手撸底层代码的优势,我使用了新的数据集
想要拟合这个数据集无疑会很繁琐,相较于上一个,它又增加了新的隐藏层,这样反向传播的求导过程将十分复杂,但使用Keras后,一切都简单了起来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import dataset
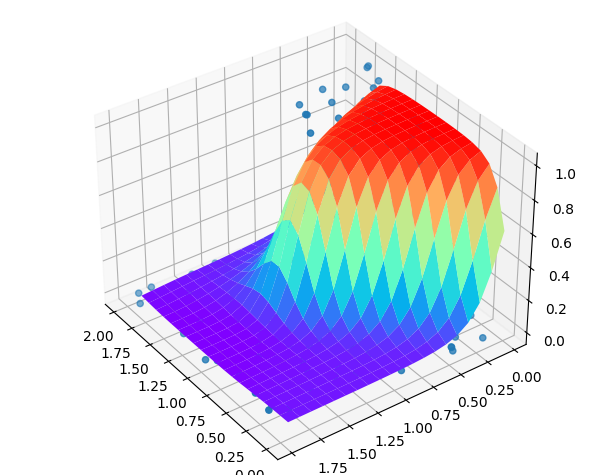
只需要小小的改一个数字就能增加隐藏层,这实在是太方便了。
效果也是非常的好