自然语言处理(NLP)——LSTM网络
文章总字数:
预计阅读时间:
使用全连接神经网络来处理自然语言未免有些乏力,之前也可以看出准确率并不是很高,这时候就需要另一种专为NLP而生的网络——LSTM网络(长短时记忆网络)。
想要学习这个网络,得先从RNN看起。循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。它的激活函数多采用双曲正切函数tanh而不是relu,当然也可以使用relu。而为了每一步操作的统一性,在第一步时会手动添加一个共同输入a0,比如一个全0向量。
而完全体的LSTM是比较复杂的
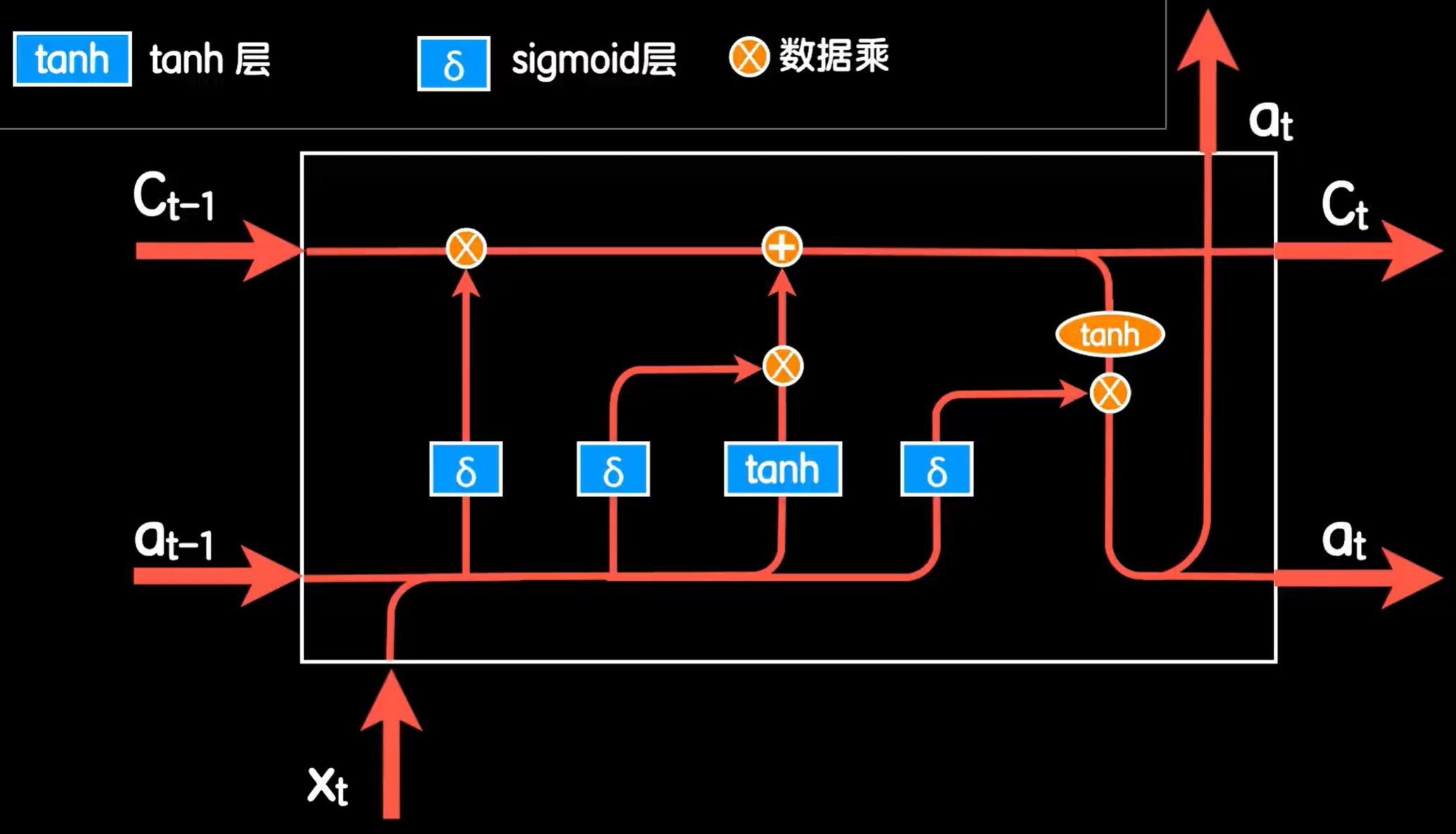
首先LSTM结构中的输出再次经过一个tanh函数,而原先的输出,就变成了一个叫做细胞状态(Ct)的东西,这个细胞状态就是LSTM能应对长依赖问题的关键,它就能让网络具有记忆和遗忘的效果。为了实现这个效果,LSTM使用了两个门来实现。第一个是遗忘门(forget gate)。使用一个sigmoid层,使其与上个细胞状态值相乘。当sigmoid为0时,就相当于把上个细胞值完全丢弃,即忘记。反之则全部记忆。而这个sigmoid层的输入则是本次词向量与上一次的输出合并的数据,这样就可以通过本次与之前的数据共同决定忘记多少之前的细胞值。第二个是更新门(update gate)。让本次的词向量与上一此的输出合并的数据在经过一个sigmoid层形成控制这个在之前标准RNN结构中用来更新的部分,即用来控制是否更新本次细胞状态值。这样就实现了记忆和遗忘的效果。而最后还有一个输出门,在标准RNN结构最后的输出也乘一个sigmoid层,这样在遇到重要词汇时产生强输出,使其难以遗忘,反之亦然。
当然这只是对LSTM的及其粗略的讲解,这篇博客有着更加详细的讲解,还有LSTM变种结构比如GRU的介绍。
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
之后就是利用LSTM对之前的网购评论数据进行学习了。
我在GitHub上找到了一个训练好的中文词向量
https://github.com/Embedding/Chinese-Word-Vectors
利用这个词向量来训练LSTM网络
首先封装一个能读取这个词向量文件的chinese_vec.py
1 | |
然后调用它读取,在经过判断是否存在后写入一个空数组。
1 | |
然后就是构造LSTM,使用Keras可以十分简单
1 | |
之后就可以开始训练了。最后可以得到一个接近90%的准确率